
[Problem]
이번주 과제 풀스택 미니프로젝트. 내가 맡은 부분은 main.html을 작성하고 main 부분에 기능을 구현하는 것이다.오늘의 문제는 크롤링하는 부분이었다. yes24에 있는 책의 URL을 통해 title, description, image를 가져오는 기능이었다.여기서 문제는 title과 description을 가져오는 것은 문제가 발생하지 않았지만 image를 가져오는데 문제가 발생했다.어떤 책은 3D로 구현되어 있지 않았지만 어떤 책은 3D로 구현해 놓아서 다르게 적용되었다.
// 3D image
#yDetailTopWrap > div.topColLft > div > div.gd_3dGrp.gdImgLoadOn > div > span.gd_img > em > img
// 2D image
#yDetailTopWrap > div.topColLft > div > span > em > img3D부분을 넣고 실행할 경우 이미지를 받아올 수 없었다.
[Try]
처음 시도한 방법은 저번에 토이 프로젝트에서 진행했을 때 사용했던 selenium을 이용하는 것. selenium 사용시 3D image 부분은 잘 가져왔다. But 2D로 작성된 URL의 image는 가져올 수 없었다. 2D로 작성된 URL의 image를 가져오기 위해선 강제로 page를 종료하는 작업을 넣으면 해결할 수 있었지만 그렇게 작성하기에는 너무 번거로울 거라 생각이 들었다. 따라서 여러가지를 생각하다 다시 image부분의 코드를 비교했더니 중간에 3d를 넣는 부분이 따로 작성되어 있을 뿐 나머지 코드는 동일하다는 것을 알게되었다. 그래서 다시 생각한 부분은 html에 작성된 class 부분이 다른 곳에 중복으로 사용되어 있지 않다면 class명을 이용하여 image의 정보를 받아 올 생각을 하였다.
@app.route("/booksbooks", methods=["POST"])
def book_post():
nickname_receive = request.form['nickname_give']
url_receive = request.form['url_give']
review_receive = request.form['review_give']
star_receive = request.form['star_give']
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(url_receive,headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
title_receive = soup.select_one(#yDetailTopWrap > div.topColRgt > div.gd_infoTop > div > h2).text
desc_receive = soup.select_one(#infoset_introduce > div.infoSetCont_wrap > div.infoWrap_txt > div).text
#이미지부분 클래스로 받아오기
image_receive = soup.select_one(#yDetailTopWrap > div.topColLft > div > span > em > img)['src']
doc = {
'nickname':nickname_receive,
'title':title_receive,
'desc':desc_receive,
'image':image_receive,
'review':review_receive,
'star':star_receive
}
db.booksbooks.insert_one(doc)
return jsonify({'msg':'저장완료!'})image_receive부분을 수정했다.
[Solution]
title_receive = soup.select_one('.gd_name').text
desc_receive = soup.select_one('.infoWrap_txt').text
#이미지부분 클래스로 받아오기
image_receive = soup.select_one('.gImg')['src']이렇게 수정을 했고 결과적으로 크롤링할 수 있었다. 따라서 위에 title부분과 desc부분도 class로 받아 오는 형식으로 변경하였다. 결과적으로 모든 부분에서 크롤링이 가능했다.
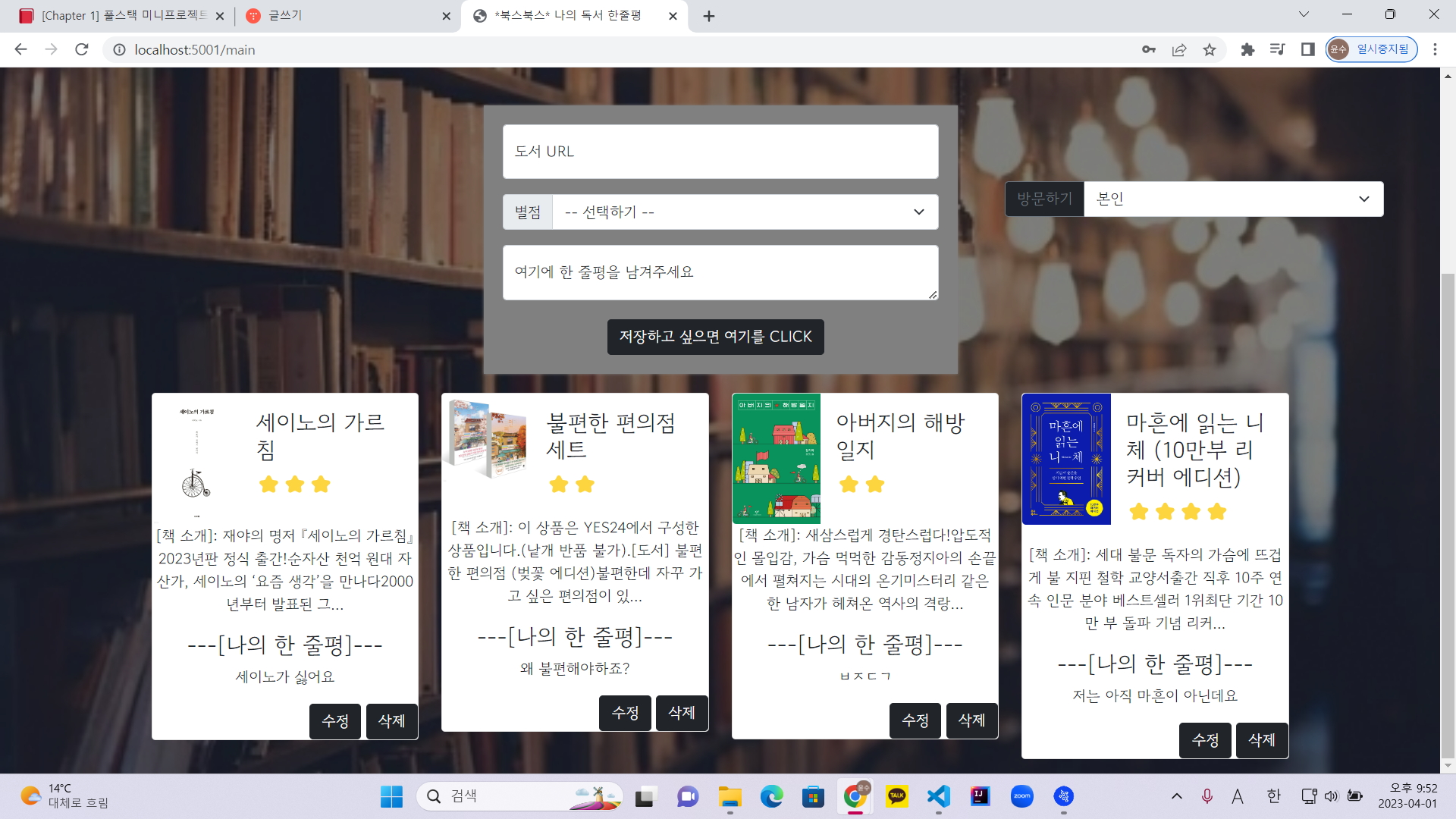
[Conclusion]
결과적으로 bs4를 이용한 크롤링을 할 때 배운 내용 외에도 다양한 방법으로 크롤링이 가능하다는 것을 깨달았다.
But 한가지 고려해야하는 것은 웹페이지 내에 중복되는 클래스나 id가 없을 시에 가능한 방법이다. 그리고 ' '을 씌워 가져와야 한다는 것이 중요하다. Selenium을 이용하는 방법도 있지만 쉽고 페이지를 여는 동작없이 쉽게 크롤링할 수 있는 방법이 있다면 그 방법을 선택하는게 맞다 생각된다.
'Self Dev. > TIL' 카테고리의 다른 글
| 2023.04.05 TIL - <1주차 과제> [match 메소드, 정규표현식] (0) | 2023.04.09 |
|---|---|
| 2023.03.31 TIL - 풀스택 미니프로젝트(books-books) (0) | 2023.04.02 |
| 2023.03.26 - 토이 프로젝트 (점심 메뉴 월드컵) (0) | 2023.03.26 |
| 2023.03.25 - 항해 99 TEST[Bucket-List] (0) | 2023.03.25 |
| 2023.03.19 TIL - 토이 프로젝트[TO-DO LIST] (0) | 2023.03.24 |